
What I Learned at AI Engineer Paris Conference, Sep 2025
My key takeaways and learnings from AI Engineer Paris, where the AI engineering community came together this September to discuss AI agents

Disclaimer: I am not affiliated with any company that I mention below (except Pactum, where I work as head of product engineering). All opinions below are my own.
—
I haven’t been to any engineering-focused conference for a while, so I decided to go to one. So Carl and I were flying from Tallinn to visit the conference in Paris, with the goal to, hopefully, bring back learnings back to Pactum (where both of us work) for our engineering org. I was afraid there would be a lot of sales people who will only sell me things, and not much “meat”. I am happy it turned out the other way around - a lot of cool engineers & AI enthusiasts visited the conference, from Nvidia, Shopify, Sentry, BMW, Mistral, Spotify etc. All right, let’s dive into the learnings!
All themes revolved around building and deploying AI agents.
Building and optimising data layer for AI agents
CEO of Neo4J, Emil Eifrem, talked about how they think about building a data layer optimised for agents. His talk was actually pretty technical and good. Emil’s main point was that data layer for AI agents would have to have these 4 properties:
Handle structured, unstructured, and semi-structured data.
Consistently and reliably extract entities from unstructured data.
Link entities across memory and application data.
Disambiguate first party and derived data.
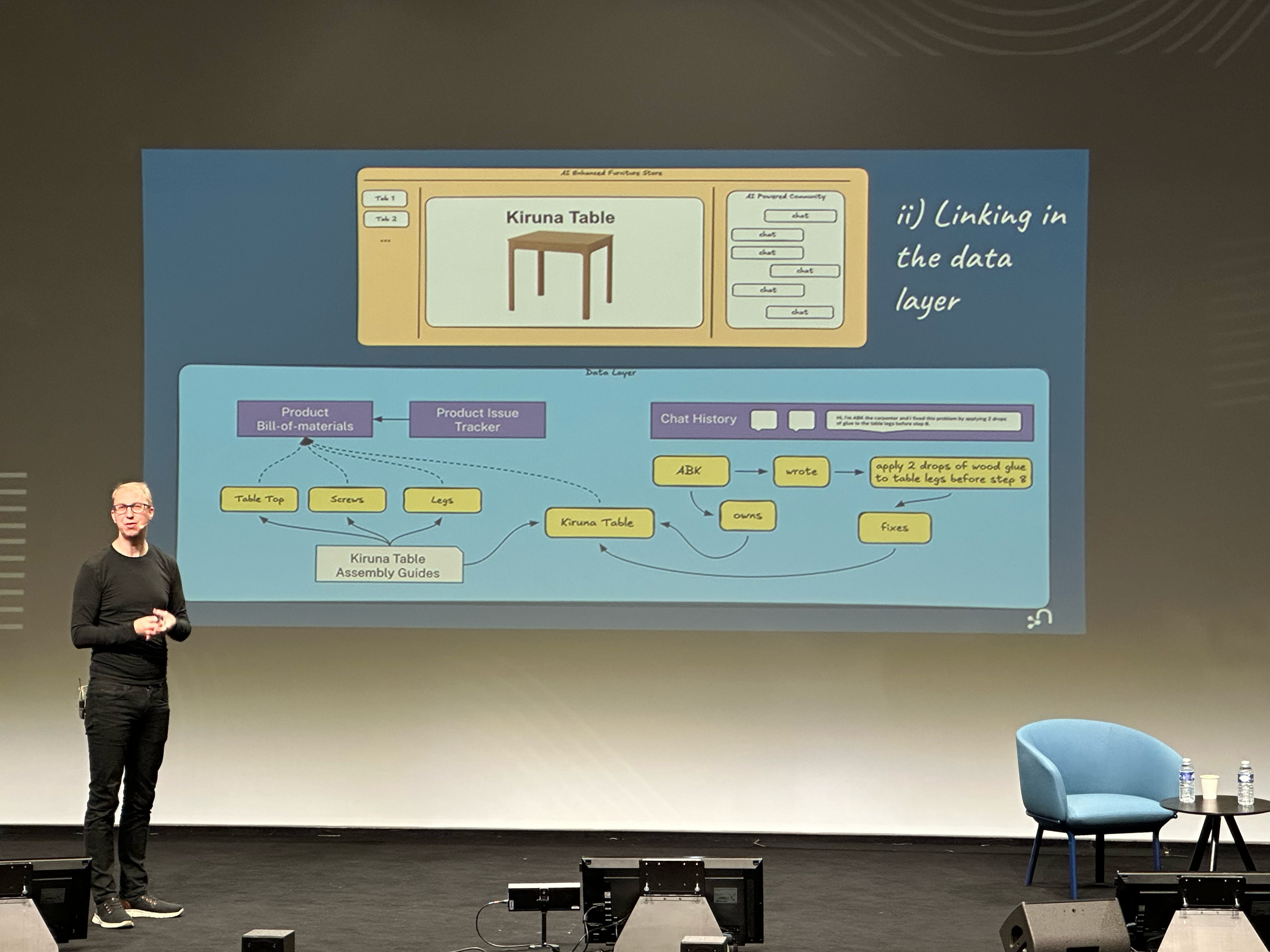
Emil was honest that in Neo4J they are pretty much still building out those properties optimised for AI agents usage.
My takeaway. It’s an interesting idea to use native graph database as a knowledge graph, to do advanced techniques such as GraphRAG on top of it etc. Right now my knowledge on Neo4J and graph databases is limited, but my approach, as an engineer, would be the following regarding the data layer for AI agents:
First, start simple. Understand how you will do evals of your agentic features. Now you have a feedback loop. Here goes your test-first approach.
And if you use Postgres, for example, stick to it, for now. First, throw all you need into a context window. If that doesn’t work, try giving your agent useful tools (e.g. exposed over MCP) to query your data. That might be a powerful enough and simple technique for your agent to read your data.
If giving your agent tools that manipulate your data layer is not good enough, as reflected by your evals test pipeline, try RAG with pgvector. Optimise RAG parameters (chunking, embedding model etc). Your evals will tell you if you move in the right direction.
That didn’t work either? Step back. Think about your agentic workflows. Can you split your big use-case into smaller steps? Agan, think about agentic workflow primitives.
Did I mention that by now you probably need to ship your feature? If your test evals are good enough, ship, and learn from your users and results. Definitely have monitoring and tracing and check evaluation results.
If you have all those basic steps in place with solid feedback loops and you want to optimise even further, sure, go ahead and explore graph databases and cool things like GraphRAG. But don’t over-engineer at first. Move with small, safe steps, optimising only when strong feedback loops are in place.
Did I mention AI evals multiple times? Let’s explore them in more detail!
AI Evals: what’s now and what’s coming
Code is deterministic. AI agents using LLMs are usually non-deterministic. Mastra defines evals in the following way (source):
Evals are automated tests that evaluate Agents outputs using model-graded, rule-based, and statistical methods.
I chatted to CTO of Orq.ai at the conference, and engineers from Arize.com. Both companies are focusing on building out infra and tools for evals as part of their AI platform offering. Orq, for example, builds sophisticated evals guided by agent that is able to evaluate multiple steps of your agent run. Arize also has a lot of cool tooling, for different use-cases of evals. Both Arize and Orq are actively iterating on their evals product, learning based on how their customers use evals. There is no established single set of “best practices” yet, only active exploration.
@swyx, who gave a talk at the conference, said that he knows that Claude Code engineers still say that “Claude Code evals are still a lot about the vibes” [everybody laughed at the room]. It was semi-joke, but with a point. Swyx, I think, wanted to underline the point that the industry as a whole is still learning about how to do AI evals. It’s art & science and the wild west still.

My takeaway. Everyone is learning and exploring how to do AI evals, as it’s totally a different beast from a traditional testing approach. One thing is clear though - it’s crucial to test your agents and gain feedback loops, both in your CI/CD pipeline and in production through observability. AI evals is a complex topic and is 100% worth exploring and learning about if you are serious about deploying AI agents to production. Just to give you a sense of techniques, below is a visualization from open-source engineering platform, Langfuse, on online & offline flows of AI evals and how they interact together:

System prompt engineering via meta prompting and explanations from AI evals
There was a really cool talk by co-founder of Arize, Aparna Dhinakaran. It opened my mind how you can do system prompt engineering at scale in a data-driven way. Here is the flow:

Let’s say you have v1 of your system prompt for your AI agent. If you deploy a customer support AI agent, maybe your system prompt says something along the lines of “You are a helpful customer support agent. Try to help customers to resolve the issue”. I am oversimplifying with this description of course. Usually your system prompt would include a lot of instructions and examples as well. The whole point is - it’s your first version, and over time you would like to improve your system prompt. How do you do it?
You deploy your AI evals, for both offline (CI/CD) and online (production observability). Important bit now - your AI evals include not only some score (be it label or a normalised score from 0 to 1), but also an explanation.
Now here is a cool bit. After your AI agent got some traffic, you will have a lot of those AI evals with scores and explanations. For example, if one agent output was not so good, your AI eval might give it a score with label “bad” or “0” with an explanation: “Agent output did not clarify the problem of the customer”.
You then write a meta prompt with the goal to improve the system prompt. You feed all corpus of generated explanations from AI evals into your meta prompt, and your meta prompt generates a better system prompt.
For example, your system prompt might look like this (oversimplifying of course, just to show the point):
”””
Your goal is to improve a system prompt. I will give you my current system prompt and all explanations from AI evals. Based on this input, please generate new improved version of system prompt, taking into account feedback from explanations from AI evals.
Current system prompt: <system prompt>
Explanations from AI evals results: <array of explanations>
”””
Voila! You have your second iteration of a system prompt. Now you can evaluate your system prompt with your offline AI evals and if it improves performance, you deploy it to production. Once you gather enough production data of explanations from AI evals, you can re-run meta prompt again to improve a system prompt further.
This is data-driven way to improve your system prompt!
BMW explores GUI-based Agents
BMW gave a talk about how they explore GUI-based agents to manipulate their Android UI. It might be useful for some use-cases, where usage via strict API is not practical for one reason or another. GUI agents or browser-based agents might be a hybrid way to interact with some external system that you don’t have full control over or the one that changes rapidly. Just keep it in mind and consider using this tool if it helps you solve some integration problem that you have.
LlamaIndex gave a cool talk on cloning NotebookLM. Structured data extraction
My key takeaway is the following: the industry has solved the use-case of structured data extraction pretty well. To clarify, I mean the mapping of unstructured data to a structured one.
As stated on IBM docs on one of prominent use-cases for LlamaIndex:
Structured data extraction: LLMs process natural language and extract semantically significant details such as names, dates, addresses and figures and present them in a consistent, structured format regardless of the original source. Once the data is structured, it can be sent to a database or further analyzed with tools such as LlamaParse.
This use-case is very important for the whole industry. For example, in Pactum, we had to solve the same problem of mapping of unstructured data to a structured one. We used Gemini model and did our own context/prompt engineering. Today, there are more and more abstractions and tools available that help to solve this problem “out of the box”.
Incident management assisted by AI agents
I had opportunity to chat with engineers from DataDog at their booth. One thing is crystal clear: we are 100% moving towards AI-assisted incident management, and I think that’s a great use-case for AI agents.
DataDog, for example, has been building a lot of agentic features into their observability product, and at least their engineers say that they dog-food their own product to help them resolve their incidents/bugs faster with the help of AI agents.
The future, or should I say the present, looks like this. You get an error report from Sentry/DataDog or whatever you are using, the AI agent will do the first run trying to debug the issue, looking at all relevant error logs and traces. AI agent will try to correlate that with recent changes in your codebase, looking through your git history. Agent will use all relevant info to troubleshoot and try to solve the issue itself, or will ask clarifying information from you. In best case, agent solves the issue itself in one go. At worst case, it serves you, an engineer, as an assistant, whom you can guide to help you out, by asking it to check out logs and report you the findings etc.
I suggest you explore, experiment and adopt AI-assisted incident management at your workplace.
Docker with MCP Toolkit
Docker claims that with its MCP toolkit it’s very easy to host MCP servers locally. Probably for production use-cases as well (I don’t know). I haven’t delved into details yet, but if you have more experience dealing with Docker MCP toolkit and have opinions/thoughts, feel free to share in the comments.
Sentry: using agent inside their MCP server
Just an interesting pattern to report. Sentry exposes its MCP server. Inside its MCP server, they don’t just wrap API calls, but they have an agent that orchestrates and calls different APIs and then gives the final response.
Voice AI got crazy good! Kyutai blew my mind
The last presentation of the conference was by Kyutai. And it really blew my mind. They solved full duplex voice to voice conversation, handling interruptions natively, excellent text to speech and speech to text, seamless switching between languages, and fully recognizing all actors who speak. The presentation is here on YouTube. I strongly recommend you to watch, it’s fascinating!
And that’s a wrap!
Well, here are my random thoughts from the conference. I hope you took something useful away. One thing is clear: it’s a wild west with AI agents. so stay humble to keep learning, and at the same time be bold and curious! For more perspective on how AI agents change engineering, I suggest you to check Kent Beck’s article called Programming Deflation.

Also, we are hiring software engineers to Pactum. Feel free to check out pactum.com/careers.
Happy to continue the conversation in comments.
Thanks for article Vitalii! It was very useful and interesting!